Comparative Systems Service¶
Revised: February 22, 2024
Overview¶
The Comparative Systems Service combines together functionality from three different tools and data from the legacy PATRIC system: the Protein Family Sorter, Pathway Comparison Tool, and Subsystems Data. and also includes subsystems (1,2), a set of functional roles that together implement a specific biological process or structural complex and can also be generalized as pathways. Up to 500 genomes can be compared. All three tools use the two protein families, PATtyFams (3), that are assigned in the BV-BRC annotation process known as RASTtk (4). The global families, known as PGFams, can be used for cross genus comparisons. The local families, PLFams, are for intra-genus comparisons. Pathway maps are represented using KEGG (5).
See also¶
Using the Comparative Systems Service¶
The Comparative Systems submenu option under the Services main menu (Genomics category) opens the Comparative Systems input form (shown below). Note: You must be logged into BV-BRC to use this service.

Options¶
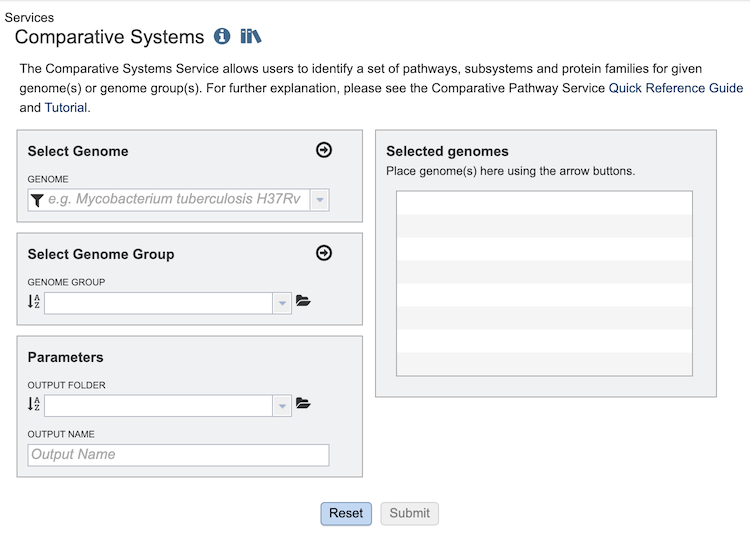
Select Genome¶
The service can accept selected genomes and genome groups. To include any genome (reference, representative, other public, or private genomes), click on the filter icon in the text box in the “Select Genome” box to narrow the selection and deselect the categories that are not of interest. Typing in the text box will display a list of matching genomes. Clicking on the genome name selects it, and clicking on the arrow icon in the top right of the box adds it to the “Selected Genomes” list. Multiple genomes can be added. This service uses genomes that are annotated within the BV-BRC resource (they can be private or public genomes). You can annotate your contig files using the Annotation (https://www.bv-brc.org/app/Annotation), Comprehensive Genomic Analysis (https://www.bv-brc.org/app/ComprehensiveGenomeAnalysis) or Metagenomic Binning (https://www.bv-brc.org/app/MetagenomicBinning) services.
Select Genome Group¶
To include a genome group in the analysis, click on the down arrow in the text box in the “Select Genome Group” box. This will display a list of all the genome groups, with the most recently created appearing at the top of the list. Selecting a group and clicking on the arrow icon in the top right of the box adds it to the “Selected Genomes” list. Multiple genome groups can be added.
Selected Genomes¶
This box displays the list of all of the genomes and/or genome groups selected to be included in the analysis.
Parameters¶
Output Folder: The workspace folder where results will be placed.
Output Name: The name users specify for the completed job.
Output Results¶
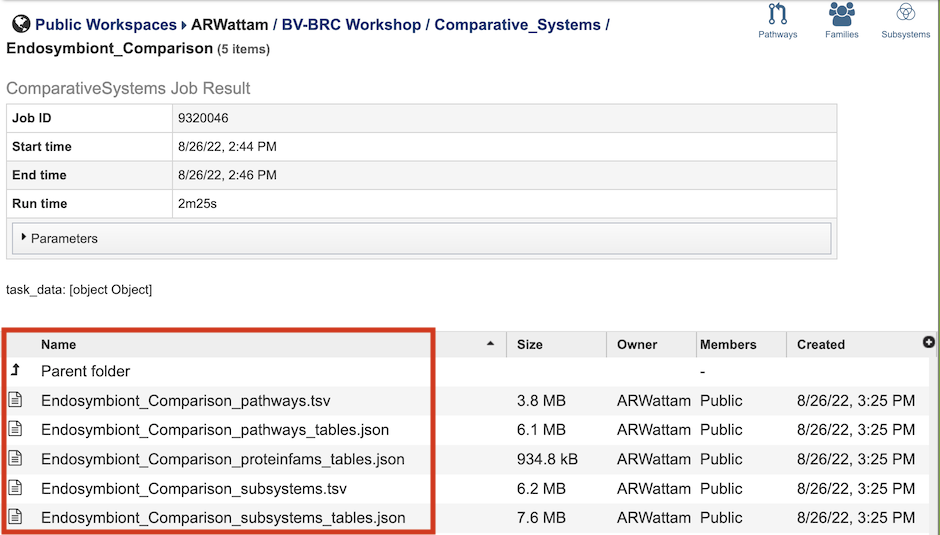
The Comparative Systems Service generates several files that are deposited in the Private Workspace in the designated Output Folder. These include the following, where [output_name] is replaced with the Output Name entered on the input form:
[output_name]_pathways.tsv - Tab-separated-value (TSV) format file containing all the pathways and genes found across all the genomes in the selection.
[output_name]_pathways_tables.json - Javascript Object Notation (JSON) format file of the pathways and genes found across the genomes in the selection. Files of this type are used by the system for structured data handling.
[output_name]_proteinfams_tables.json - JSON-format file containing all of the protein families found across all the genomes in the selection.
[output_name]_subsystems.tsv - TSV-format file containing all of the subsystems found across all the genomes in the selection.
[output_name]_subsystems_tables.json. - JSON-format file containing all of the subsystems found across all the genomes in the selection.
The output from the Comparative Systems Service can be accessed and analyzed from three different BV-BRC tools: the Pathway Comparison Tool, Protein Family Sorter, and Subsystems Data. Each of these can be accessed by clicking the corresponding icon in the upper right corner of the results page.
![]()
Pathway Comparison Tool¶

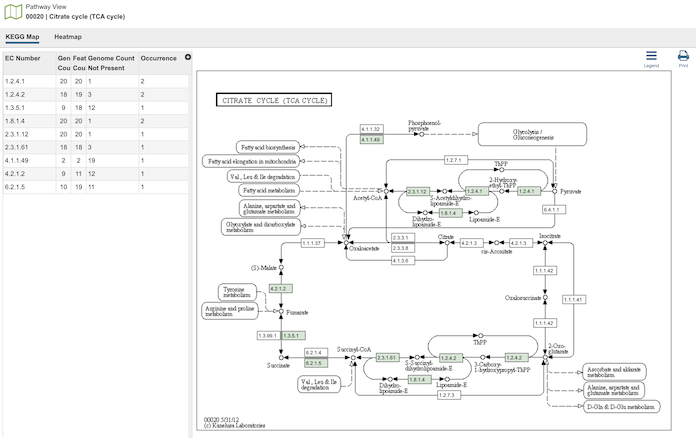
Clicking the Pathways icon opens the The Pathway Comparison Tool, which allows researchers to identify a set of metabolic pathways based on taxonomy, EC number, pathway ID, pathway name and/or specific annotation type. Refer to the Pathway Comparison Tool Quick Reference Guide for details on how to use this tool.
Protein Family Sorter¶
![]()
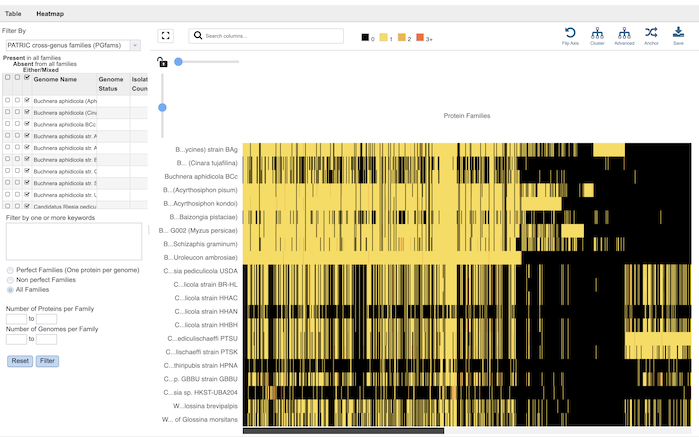
Clicking the Families icon opens the the Protein Family Sorter, which allows users to select a set of genomes of interest and examine distribution of protein families across the genomes. Refer to the Protein Family Sorter Quick Reference Guide for details on how to use this tool.
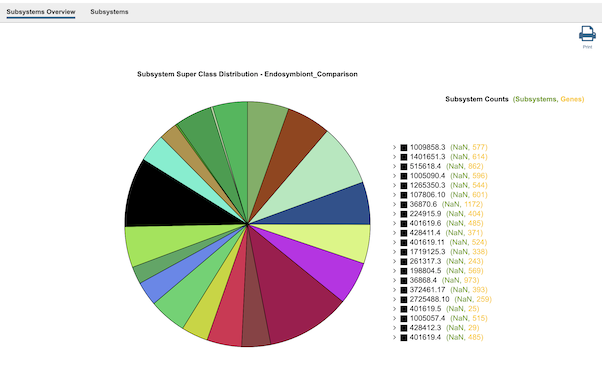
Subsystems Data¶

Clicking the Subsystems icon opens the Subsystems Data page which includes a distribution pie chart that summarizes the functionality and genes across all genomes selected and additional information. Refer to the Subystems Data Quick Reference Guide for details on how to use these data.
References¶
Overbeek, R. et al. The subsystems approach to genome annotation and its use in the project to annotate 1000 genomes. Nucleic acids research 33, 5691-5702 (2005).
Overbeek, R. et al. The SEED and the Rapid Annotation of microbial genomes using Subsystems Technology (RAST). 42, D206-D214 (2013).
Davis, J. J. et al. PATtyFams: Protein families for the microbial genomes in the PATRIC database. 7, 118 (2016).
Brettin, T. et al. RASTtk: a modular and extensible implementation of the RAST algorithm for building custom annotation pipelines and annotating batches of genomes. Scientific reports 5, 8365 (2015).
Kanehisa, M., Furumichi, M., Sato, Y., Kawashima, M. & Ishiguro-Watanabe, M. KEGG for taxonomy-based analysis of pathways and genomes. Nucleic Acids Research (2022).