Influenza Reassortment Analysis Service¶
Overview¶
The idea behind the Influenza reassortment analysis tool “TreeSort” is the observation that if there is no reassortment, then the evolutionary histories of different segments should be identical. TreeSort then uses a phylogenetic tree for one segment (e.g., the HA influenza A virus segment) as an evolutionary hypothesis for another segment (e.g., the NA segment). We will refer to the first segment as the reference and the second segment as the challenge. By trying to fit the sequence alignment of the challenge segment to the reference tree, TreeSort identifies points on that tree, where this evolutionary hypothesis breaks. The “breaking” manifests in the mismatch between the divergence time on the reference tree (e.g., 1 year divergence between sister clades) and an unlikely high number of substitutions in the challenge segment that are required to explain the reference tree topology under the null hypothesis of no reassortment.
TreeSort has demonstrated very high accuracy in reassortment inference in simulations (manuscript in preparation). TreeSort can process datasets with tens of thousands of virus strains in just a few minutes and can scale to very large datasets with hundreds of thousands of strains. (This overview is from https://github.com/flu-crew/TreeSort/blob/main/README.md)
NOTE¶
The current version of TreeSort can ONLY be used with nucleotide sequences of an Influenza virus. We hope to provide an updated version in the near future that can be used with common segmented viruses.
See Also¶
TreeSort Service Tutorial (TODO)
Using the TreeSort Service¶
In the main menu, Influenza Reassortment Analysis is located under TOOLS & SERVICES and Viral Tools.
Note: You must be logged into BV-BRC to use this service.

Parameters¶
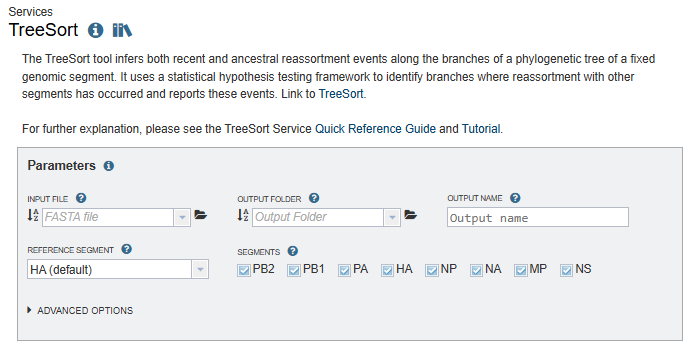
Input file¶
NOTE: If the following instructions are not followed, your input file can’t be submitted for analysis!
TreeSort has very specific requirements for the format of strain names and segments in the headers of your FASTA file.
Segment name¶
Influenza segment names in the FASTA file headers are limited to PB2, PB1, PA, HA, NP, NA, MP, and NS.
The segment name must be within | characters with no whitespace around the name. For example, |HA|.
Strain name / identifier¶
The strain names in your FASTA headers can be formatted in one of 3 ways:
The strain name is everything that remains after the segment name is removed.
The strain name starts with “EPI_ISL_” followed by a numeric (integer) value.
A strain name starts with A, B, C, or D followed by 3 to 5 spans of text inside / characters. For example: A/swine/Iowa/A02635718/2021. In this format, | characters are not allowed in the strain name.
Additional requirements¶
Your FASTA file should have sequences for at least 10 strains (one sequence per segment).
Sequences for at least 2 segments must be provided for each strain.
Every strain should have a sequence for all segments referenced in the file. For example, if one strain has sequences for HA, NA, and PB1, all other strains in the file should have sequences for HA, NA, and PB2, as well.
As soon as you select a FASTA file from your workspace, it will be automatically validated. If there are problems with the file, an error message will be displayed with suggestions about how to resolve the error(s). If your FASTA file is successfully validated, a summary of the number of strains and segments will be displayed. Please confirm that the summary is consistent with the contents of your file.
Output folder¶
The directory in your workspace where a directory will be created for the TreeSort results.
Output name¶
The name of the directory that will be created under “Output folder”. This name will also be used for the primary results filename (output name.tre).
Reference segment¶
Reassortment events are acquisitions of 1 or more novel segments relative to this (fixed) reference segment.
Segments¶
Select at least 2 segments to include in the analysis.
Advanced options¶
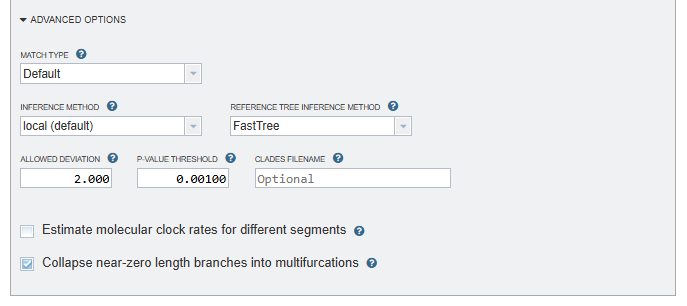
Inference method¶
local: (default)
mincut: The mincut method:
Always determines the most parsimonious reassortment placement, even in ambiguous circumstances.
Uses the reassortment test to cut the reference phylogeny into the optimum (smallest) number of non-reassorting parts with theoretical guarantees on optimality.
Is more robust than the current “local” method in many instances, and does not result in “uncertain” reassortment inferences with the ‘?’ annotation.
Reference tree inference method¶
The tool that will be used to infer the reference tree:
FastTree: (default)
Infers approximately-maximum-likelihood phylogenetic trees from alignments of nucleotide or protein sequences.
Can handle alignments with up to a million of sequences in a reasonable amount of time and memory.
IQ-Tree (recommended for better accuracy)
A fast search algorithm (Nguyen et al., 2015) to infer phylogenetic trees by maximum likelihood.
Allowed deviation¶
Maximum deviation from the estimated substitution rate within each segment. The default is 2: The substitution rate on a particular tree branch is allowed to be twice as high or twice as low as the estimated rate. The default value was estimated from the empirical influenza A data.
P-value threshold¶
The cutoff p-value for the reassortment tests: the default is 0.001 (0.1 percent). You may want to decrease or increase this parameter depending on how stringent you want the analysis to be.
Clades filename¶
The path to an output file where clades with evidence of reassortment will be saved.
Estimate molecular clock rates for different segments¶
Estimate molecular clock rates for different segments, assuming equal rates.
Collapse near-zero length branches into multifurcations¶
Collapse near-zero length branches into multifurcations (by default, TreeSort collapses all branches shorter than 1e-7 and then optimizes the multifurcations).
Buttons¶

Reset: Resets the input form to default values
Submit: Launches the classification job. A message will appear below the box to indicate that the job is now in the queue.

Output Results¶
Clicking the Jobs indicator at the bottom of the BV-BRC page opens the Jobs Status page, which displays all current and previous service jobs and their statuses.

Once the job has completed, you can view the results by double-clicking the job or clicking the “View” button on the green vertical Action Bar on the right-hand side of the page.
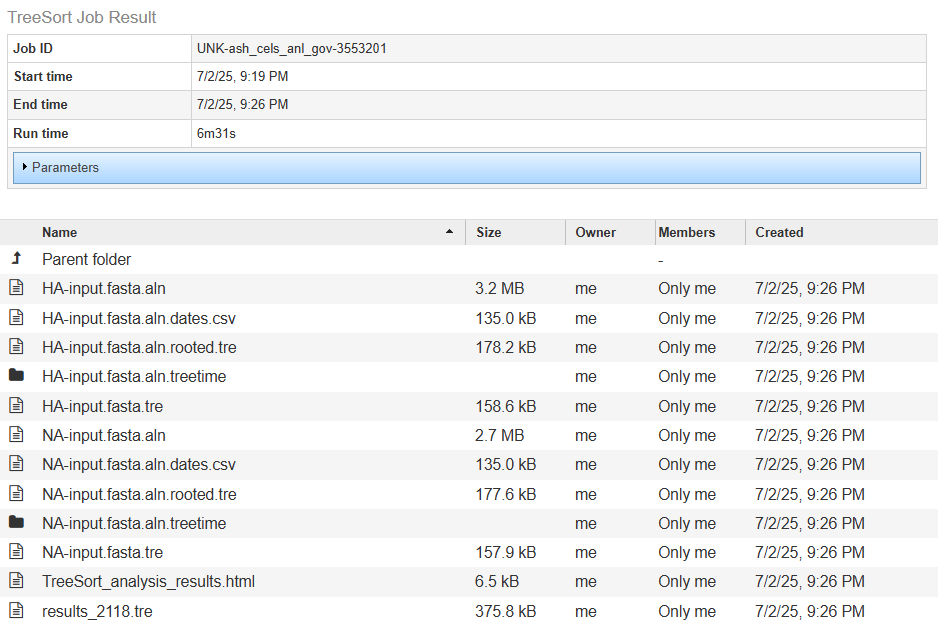
The Job Result page contains two sections:
Details about the job including its ID, its start, end, and run times, and the parameters that were used when the job was submitted (click on the arrow next to “Parameters” to view the job description formatted as JSON).
Result files generated by the TreeSort service and saved in your Workspace. The best place to start is the index.html page (see details below).
Result files¶
index.html: An overview of the analysis results with links to all files generated by TreeSort, descriptions of the file types, and guidance on how to interpret the result data. It can be accessed by clicking on the “view” icon (an eye) to the right of the Job Details, or by clicking directly on the page icon to the left of index.html in the list of result files.
reassortments.csv: A spreadsheet of the analysis results for every strain that was included in the input FASTA file. For each strain, the “is_reassorted” column will contain a “Y” if reassortment is inferred, and the “is_uncertain” column indicates the uncertainty of the inference. The remaining columns represent the segments found in the input FASTA file, and if reassortment is inferred for that strain, the reassorted segment’s column will contain the number of nucleotides that differ from the previous strain.
<output name>.xml: An annotated tree file in PhyloXML format where output name is the text that was entered in the Output name field. Clicking on this file’s link in the index.html file will open the PhyloXML file in the interactive Archaeopteryx viewer, providing advanced tree visualization tools.
<output name>.tre: An annotated tree file in Nexus format where output name is the text that was entered in the Output name field.
The files folder contains segment-specific intermediate files generated by TreeSort before performing the analysis.
Segment-specific files¶
These files are generated for every virus segment included in the analysis, where segment name is PB2, PB1, PA, HA, NP, NA, MP, or NS.
<segment name>-input.fasta.aln
<segment name>-input.fasta.aln.dates.csv
<segment name>-input.fasta.aln.rooted.tre
<segment name>-input.fasta.tre
<segment name>-input.fasta.aln.treetime is a folder that contains the following files:
outliers.tsv
root_to_tip_regression.pdf
rtt.csv
References¶
Alexey Markin, Catherine A. Macken, Amy L. Baker, Tavis K. Anderson, “Revealing reassortment in influenza A viruses with TreeSort” bioRxiv 2024.11.15.623781; doi: https://doi.org/10.1101/2024.11.15.623781